Most people get into machine learning by tinkering with Python scripts or running models in Jupyter notebooks. It’s fun, and it works—until it doesn’t. When your goal shifts from “making it work on my laptop” to “delivering this to real users,” things start to get messy.
Serving a machine learning model isn’t just about throwing an API around it and calling it a day. That might work for a demo, but it won’t scale, won’t survive failure, and definitely won’t play well in a team environment. So what does a production-grade ML system actually look like?
I argue that layering your machine learning operations—splitting responsibilities into well-defined, independent components—is the key. It makes your system more reliable (one error won’t bring down everything), more collaborative (teams can work on layers in parallel), and more scalable (you can train and serve multiple models efficiently).
This layered approach is about clarity. Each layer handles a distinct job, exposes only the interfaces it needs, and communicates cleanly with the next. That separation prevents duplication and makes maintenance easier. And while your system may evolve over time, starting with strong boundaries makes that evolution a lot less painful.
Layering
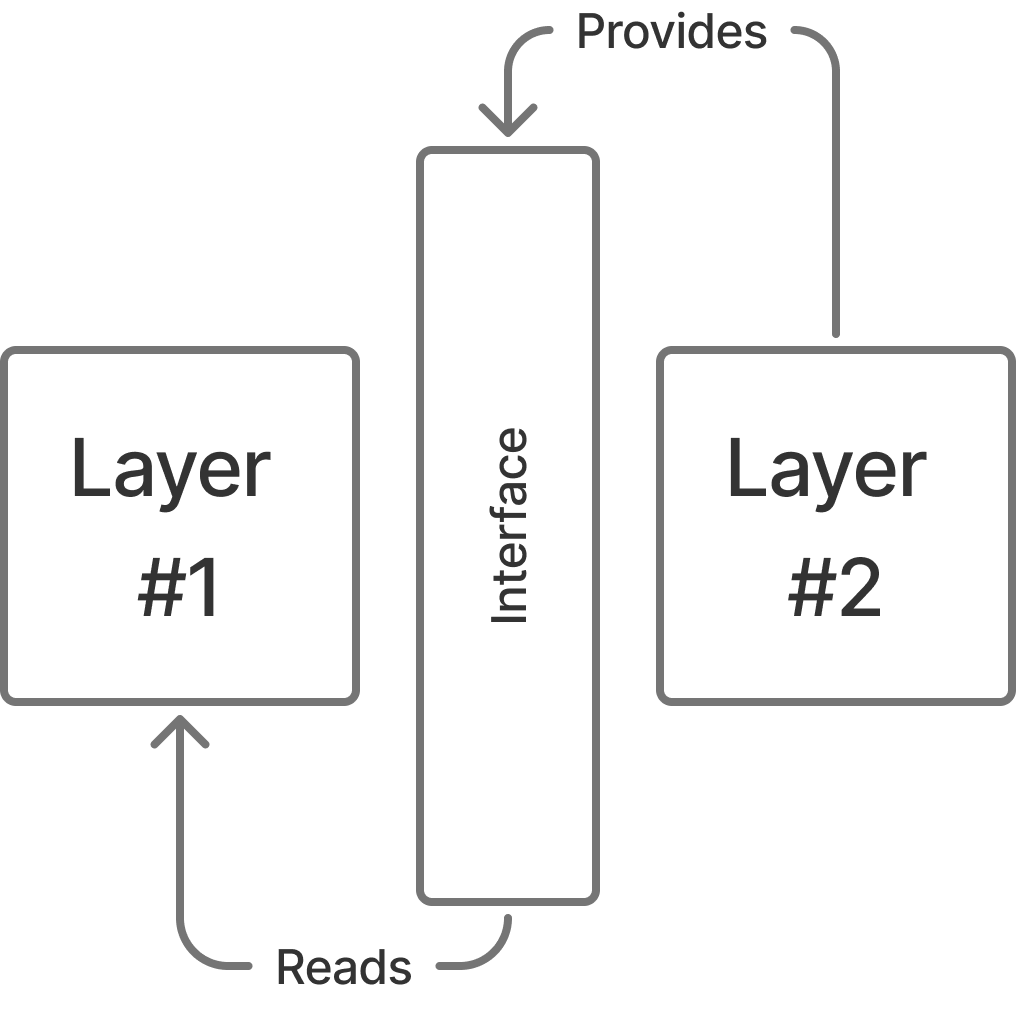
The core idea behind layering is pretty simple: take a complex system and break it into smaller, manageable parts. Each part should work independently, communicate through a clear contract, and be swappable when needed. In software engineering, this concept pops up everywhere—modules, packages, services. The names vary, but the principles are surprisingly consistent.
First, each layer should be self-contained. It shouldn’t need to know what’s happening inside the others to function. Second, it must expose an interface—a clear way to interact with it. Third, because of that independence, you can reuse or even replace a layer if its requirements are met. This decoupling is what makes layering so powerful—and so maintainable.
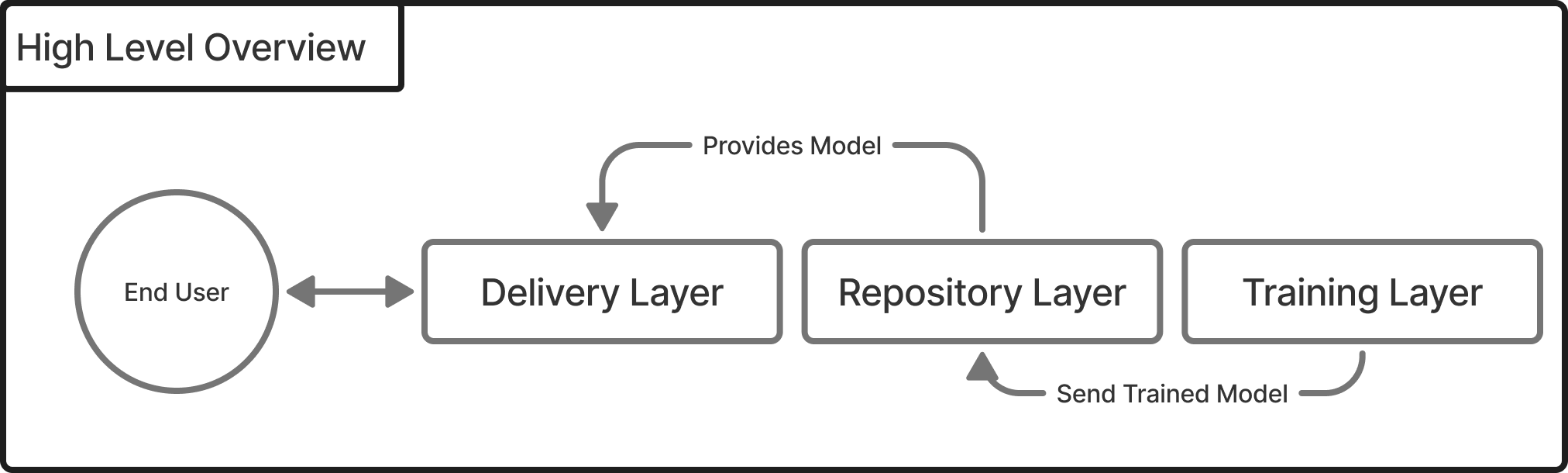
In machine learning operations specifically, I argue that you need at least three layers: the training layer, the repository layer, and the delivery layer. Each of these has a distinct job, but they need to collaborate to keep the ML pipeline running smoothly.
- The training layer is responsible for training the model.
- The repository layer stores model artifacts and metrics—everything from model binaries to evaluation scores.
- The delivery layer serves model inferences to the end user.
This separation doesn't just apply at the infrastructure level—it should be reflected in your codebase as well. Each responsibility should live in its own place, with its own files, folders, and logic.
Now, let's be real—layering isn't free. It comes with some overhead. More folders, more files, more organizing. And if you mess up the structure, you can end up with more chaos than clarity. Bad layering is worse than no layering at all.
But the upside is massive. A properly layered system is reliable. If one layer fails—whether from a bug, a crash, or even a malicious attack like a denial-of-service—it won’t take the whole system down with it. You isolate risk. You localize failure. And that’s a huge win in production environments.
So let's break down each layer. What does it do? What kind of interface should it provide? Let's start at the beginning—with the training layer.
Training Layer
When people think of machine learning, they usually think of one thing: training the model. But if your goal is to deploy a model to real users, training isn't just about calling .fit() and walking away. It's a coordinated process with multiple moving parts—and it deserves its own internal structure.
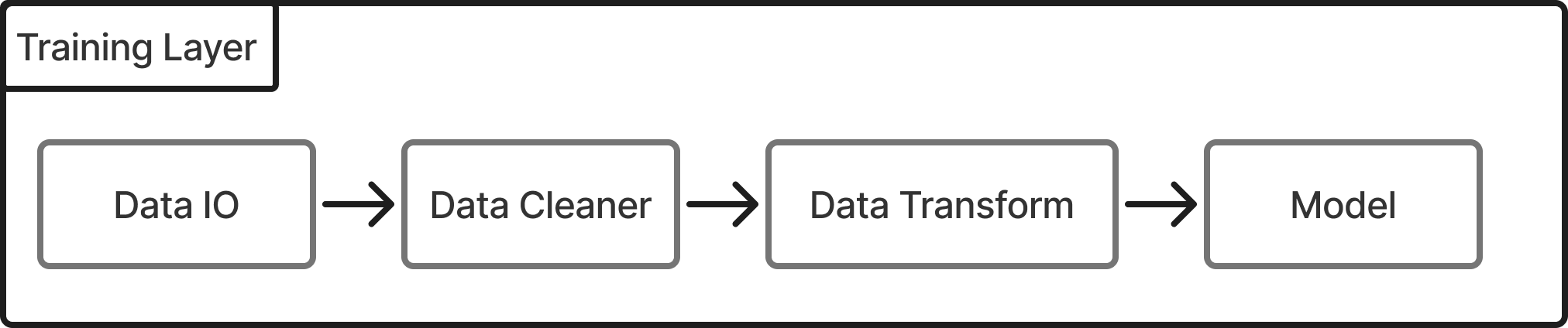
I break the training layer down into four smaller, composable sublayers:
- DataIO: for loading and saving data
- Data Cleaner: for removing junk and inconsistencies
- Data Transform: for preparing data into model-friendly formats
- Model Layer: for training, evaluating, and selecting the final model
Let's walk through each.
DataIO
DataIO is all about moving data in and out of the system. That includes fetching data from a source and writing it to a destination. Think local CSVs, cloud storage, SQL queries—you name it. When you load data, you need to define:
- Where it's coming from (e.g., local file, remote URL, database)
- What format it's in (CSV, JSON, SQL, etc.)
- How it should be represented in memory (usually as a
pandas.DataFrame)
Saving works similarly—define the destination, file type, and format. With so many combinations, DataIO deserves its own layer. It simplifies testing, makes the rest of the pipeline agnostic to data source, and enables parallel experimentation with different inputs.
Data Cleaner
Data Cleaner doesn't care where your data came from. All it knows is that it's receiving a DataFrame and needs to clean it up. That means:
- Dropping rows with missing values
- Removing outliers
- Eliminating redundant or highly collinear columns
Importantly, cleaning is not transforming. It doesn't modify values, scale numbers, or encode categories. It just prunes the bad stuff. By keeping this separate, your logic stays focused and debuggable.
Data Transform
Next comes Data Transform—where you prep your cleaned data into something a model can actually learn from. This step usually starts by splitting your data into:
- Train: used to fit the model
- Validation: used to tune hyperparameters
- Test: used to confirm final performance
Then you apply transformations like scaling, encoding, or feature engineering. But here's the key: transformations are fit only on training data, then applied to all three splits. This prevents data leakage, where your model gets accidental hints from the future.
Some people bundle cleaning and transformation together. I argue against that for two reasons:
- Cleaning doesn't rely on statistical anchors, while transformation does (e.g., min/max scaling requires computing global values).
- Cleaning doesn't need to be saved for inference—but transformation does, since end users won't know how to prep data the same way.
So we save our transformation pipeline, attach metadata, and send it to the model repository for later use.
Model Layer
Finally, we hit the Model Layer—the heart of the training stack. This layer:
- Accepts preprocessed data
- Trains one or multiple models (e.g., logistic regression, random forest)
- Evaluates them using metrics like accuracy, F1, MSE, or inference speed
- Ranks the results and picks the best one
It’s common to try out multiple models and parameter sets. This layer owns the responsibility for benchmarking them all and tagging the best result.
Once chosen, the best model is saved alongside its metadata. It becomes an artifact—ready for the delivery layer to serve later.
Bonus: because the training layer is modular and isolated, you can run multiple training pipelines in parallel. Great for experimentation. Great for teamwork.
Repository Layer
Once a model is trained, it needs a proper home—a place where it can be stored, versioned, and retrieved reliably. That’s the job of the repository layer. It acts as the bridge between training and delivery, ensuring that once a model is ready, it can be served without retraining or re-engineering.
The repository layer holds more than just the model file. It keeps everything necessary to understand and reuse the model: how it was trained, what data was used, what parameters were chosen, and what results it produced.
Importantly, the delivery layer never contacts the training layer directly. Instead, it pulls models from the repository, treating it as the single source of truth.
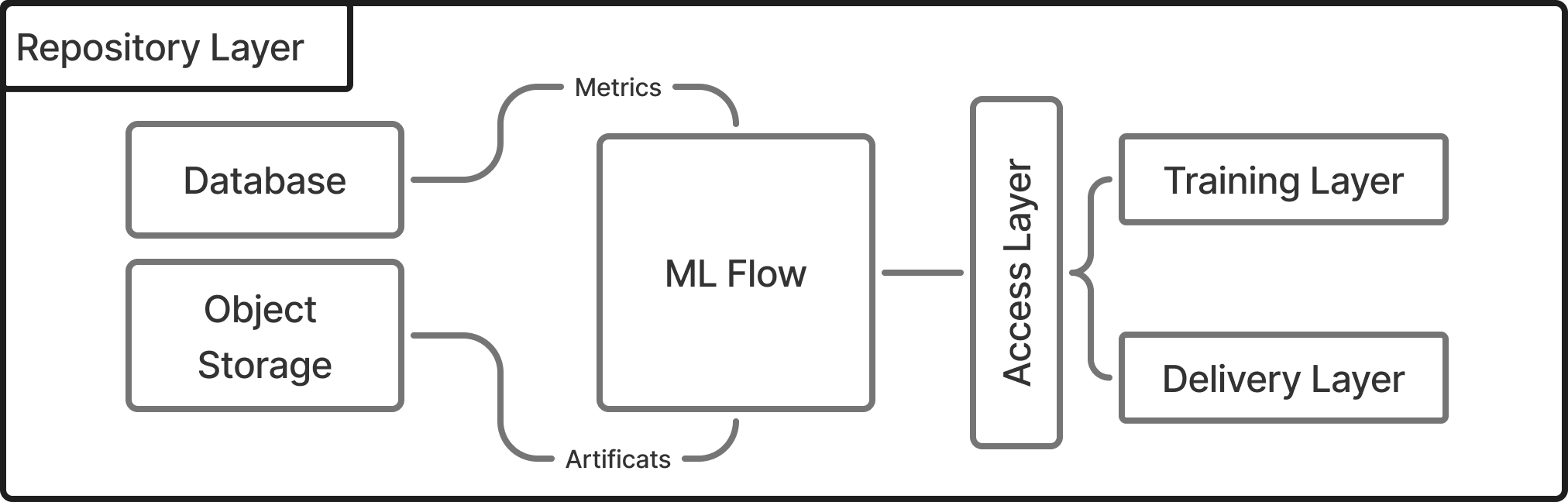
Using ML Flow
While it's possible to build your own repository system, many teams rely on [MLflow](https://mlflow.org/)—a tool designed specifically for this purpose. MLflow helps track experiments, manage models, and store metadata, all through a convenient API.
But rather than letting the training and delivery layers call MLflow directly, we introduce an access layer—a wrapper that stands between our code and MLflow.
This access layer gives us two major advantages. First, it decouples our system from MLflow. If we switch tools in the future, we'll only need to update the access layer, not the entire pipeline. Second, it lets us limit what we expose. MLflow provides a wide range of capabilities, but most of the time we only need a subset. The access layer ensures we keep our interfaces minimal and focused.
There's also a third, more strategic reason: if we ever decide to build our own repository system, the access layer shows us exactly what behavior we need to implement, reducing guesswork and unnecessary coupling.
What's Stored in the Repository
The repository layer handles two kinds of data: artifacts and metrics. Artifacts include the model file itself and any related metadata. For example, if certain columns were dropped during preprocessing, or if category mappings were used, that information is saved along with the model. This ensures that when the delivery layer loads the model, it also knows exactly how to prepare the input data.
Metrics fall into two categories. Business metrics track things like model accuracy, training time, and inference speed—everything that helps evaluate model quality. System metrics capture resource usage like CPU and RAM consumption during training. Together, these metrics let teams optimize performance over time and compare models from different training runs.
And since MLflow preserves past experiments unless manually deleted, it's easy to look back, spot trends, and make informed decisions about model evolution.
Storage Configuration
Under the hood, MLflow stores artifacts on disk and uses a SQL database for run metadata. This works fine for local experiments, but production setups typically point artifacts to cloud object storage—like S3 or GCS—and use more scalable databases like PostgreSQL.
This adds durability and makes it easier to share models across environments or teams. The repository layer is all about persistence and traceability. It keeps your work from disappearing and makes sure what you trained is what you deploy. Paired with a lean access layer, it gives your pipeline both flexibility and resilience.
Now let's move to the final piece of the puzzle: the delivery layer, where we take everything we've built and serve it to the real world.
Delivery Layer
The delivery layer is the interface between machine learning models and end users. Its main responsibility is to deliver model inference—predictions or outputs—to users in real-time. There are various ways to achieve this, and in this case, we focus on using an HTTP server as the delivery mechanism. The server exposes endpoints that users can access with proper credentials. These endpoints accept parameters, which affect the output of the model.
For example, imagine a model that predicts delivery costs. It requires inputs such as dimensions, weight, origin, and destination. These values can be encoded as parameters in the URL, either as path variables or query parameters. When a user accesses the endpoint, the server parses the input, passes it to the model, and returns the predicted value.
Phases of Delivery Layer
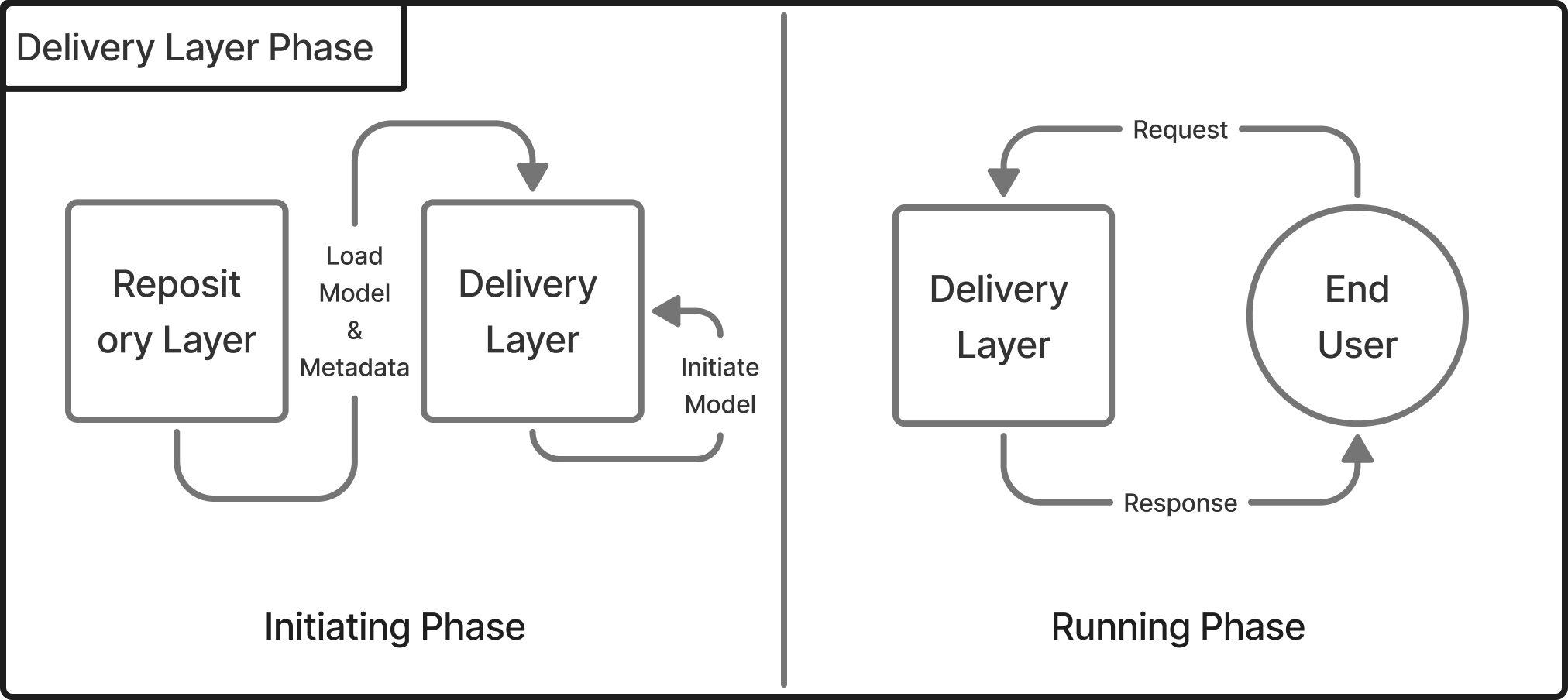
The delivery layer operates in two distinct phases: Initiating and Running.
Initiating Phase: This is the preparation stage. The delivery layer loads the available models and their associated metadata. The models are tagged for easy identification, and once loaded, the system begins parsing the metadata. This process ensures that the model's input requirements—such as the expected parameters—are understood. If any required parameter is missing, the model throws an error. The metadata also includes information about categorical variables, enabling users to select from available options.
Running Phase: Once the initiation is complete, the delivery layer enters the operational phase. It sets up all necessary endpoints. Typically, there are three routes:
- The first lists all available models.
- The second provides metadata for a given model.
- The third returns inference values based on the required parameters.
With everything in place, the delivery layer is ready to start receiving and processing requests.
Middlewares for Reliability
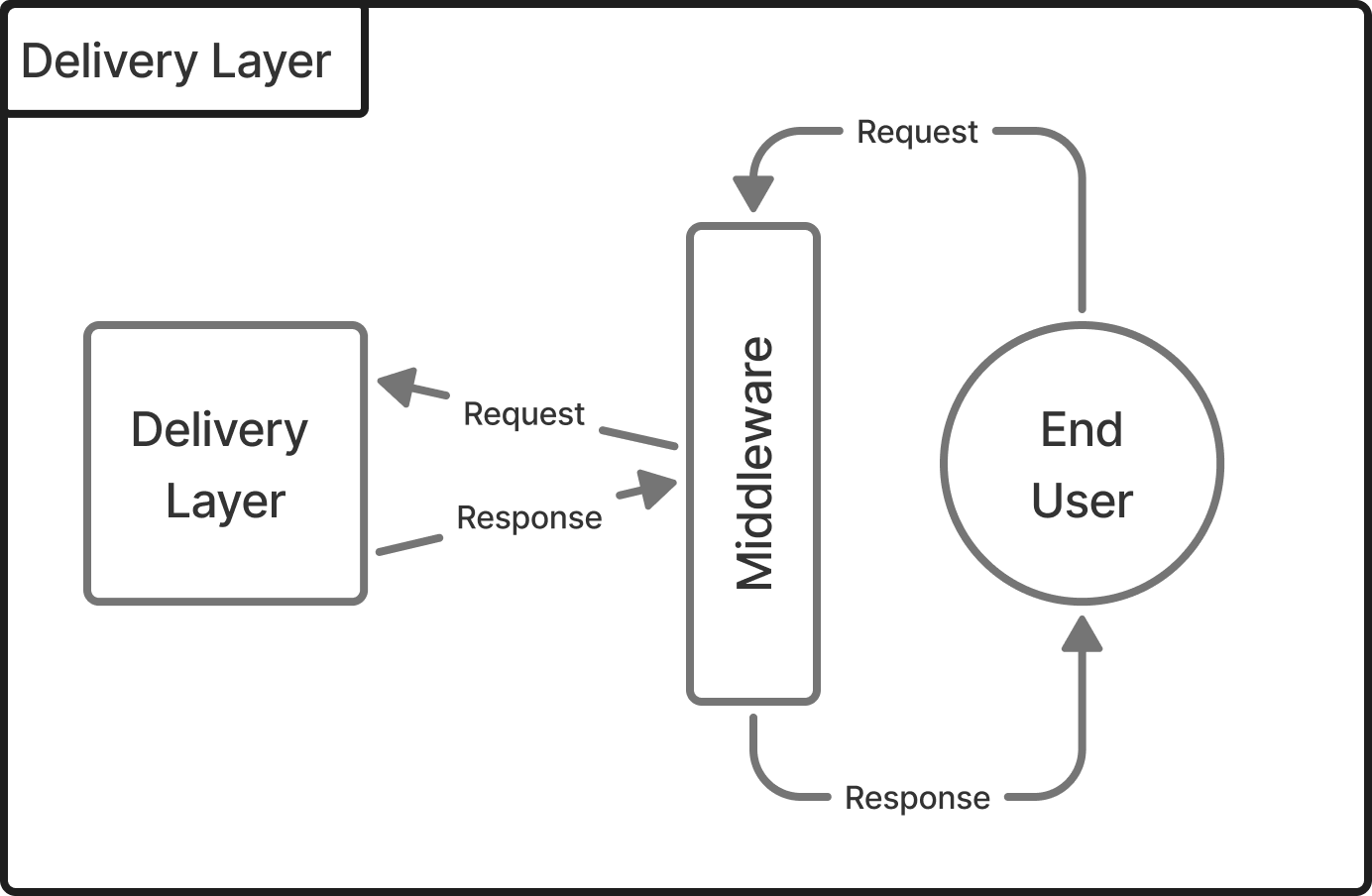
To enhance reliability, we can implement additional safeguards in the delivery layer through middleware. Middleware acts as a gatekeeper, processing requests or responses before or after they enter or exit the system. Common middleware components include:
- Authentication: This step verifies the user's identity, protecting the system from misuse. Since making HTTP requests is straightforward, authentication prevents unauthorized access to the model.
- Timeouts: Sometimes, errors in the model or data retrieval can result in requests that hang indefinitely. By setting a timeout, we ensure that each request completes within a reasonable time frame, preventing excessive resource consumption (memory, CPU) from uncompleted requests.
Updating the Model
When a newer model is available and needs to be integrated into the delivery layer, there are two main approaches:
- Reloading the models: This method allows the system to refresh the model without downtime. However, it introduces complexity, as the system must manage memory usage carefully to avoid potential memory bloat.
- Restarting the Layer: Alternatively, we could restart the entire delivery layer. While this is easier to implement, it introduces a period of downtime while the system reloads all models and metadata. This restart also provides an opportunity to reset performance metrics, which can help identify issues if performance degrades after the restart.
I recommend the second option—restarting the layer—despite the brief downtime. This approach allows us to keep the system stable and ensures that performance metrics are accurately captured from the start. Additionally, downtime can be mitigated using a double deployment strategy, where one instance of the layer remains live while the other undergoes a restart.
Conclusion
This overview presents a high-level approach to machine learning operations, detailing the transition from a simple notebook to a fully deployed server accessible by end users. While the process may seem complex, breaking it down into well-defined layers can greatly simplify its management and execution.
By adopting a layered architecture, we achieve both independence and reliability. Independence means that errors are confined within specific layers, making it easier for different team members to work on separate layers with minimal interaction. For instance, data scientists might focus on the training layer, while software engineers handle the delivery layer. While collaboration can enrich each role’s understanding of the other's domain, it can also slow down progress and complicate the workflow. Properly defining responsibilities for each layer minimizes this friction.
Additionally, different layers come with distinct requirements. The training layer relies heavily on libraries like Pandas, Scikit-learn, and Numpy for data manipulation, while the delivery layer, although it also uses Scikit-learn and Numpy, additionally requires API tools like FastAPI to manage endpoints and middleware. Combining both could lead to a bloated and less flexible system. Therefore, keeping the layers separate enhances the overall maintainability and flexibility of the deployment.
From a security perspective, layering offers significant advantages by enabling granular access control. The delivery layer, for example, doesn’t need direct access to data, so it is not exposed to data access credentials. If the delivery layer is compromised, the attacker cannot access the underlying data. Similarly, the training layer doesn’t require any credentials for endpoint access, which means that even if it is compromised, attackers can’t impersonate users to access sensitive information.
In the upcoming articles, I'll dive deeper into the implementation of each layer, sharing the specific choices made and the code used to achieve a functional machine learning operation. This hands-on breakdown will provide more context on how these principles were applied in practice.